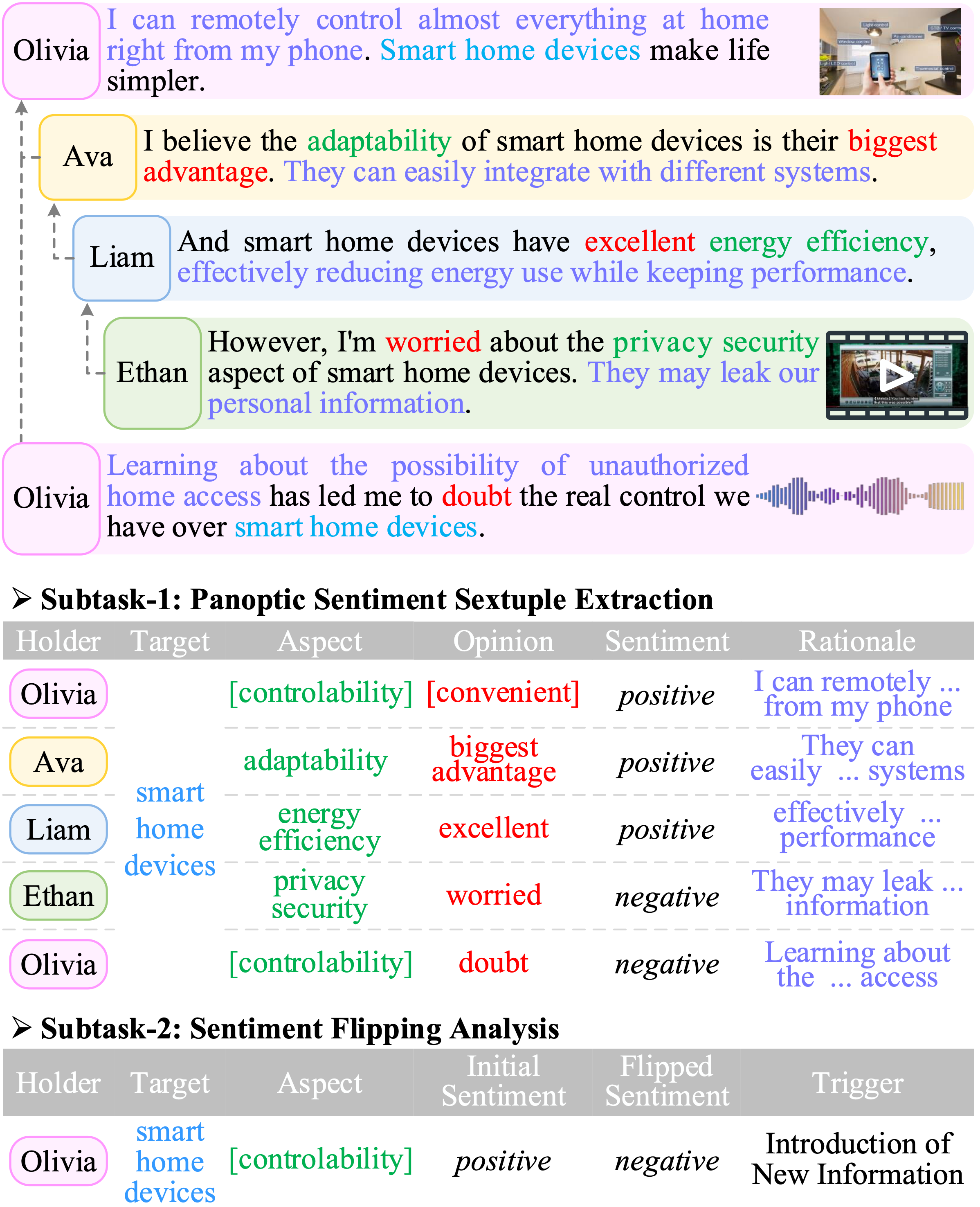
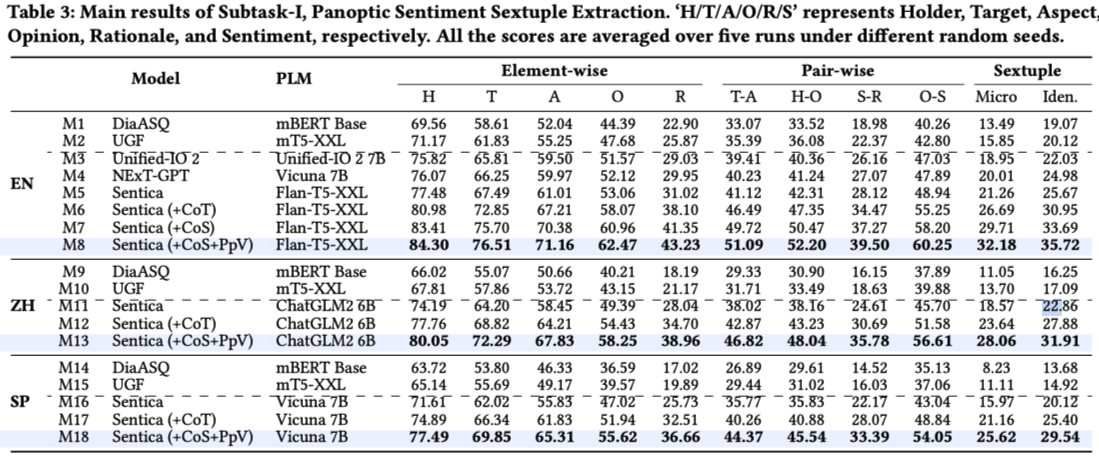
Task Definition
Subtask-I: Panoptic Sentiment Sextuple Extraction. Given a dialogue D = {u1, ..., un} with the replying structure {(ui, uj), ...} (i.e., ui replies to uj), the task is to extract all sextuples (h, t, a, o, s, r). Each utterance ui = {w1, ..., wmi} contains mi words in the text (denoted as It), occasionally with associated non-text information pieces, i.e., image (Ii), audio (Ia), video (Iv). The elements h (holder), t (target), a (aspect), o (opinion), and r (rationale) can be either the continuous text spans explicitly mentioned in utterances, or implicitly inferred from contexts or non-text modalities. s represents the sentiment category (positive, negative, or neutral).
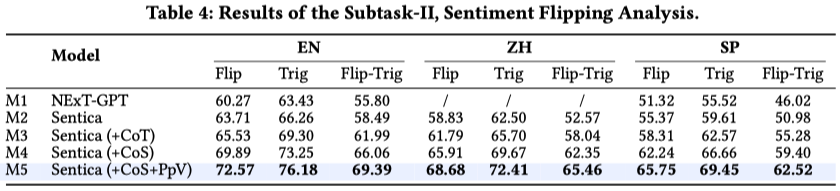
Subtask-II: Sentiment Flipping Analysis. Given input D, the same as in subtask-I, the task detects all sextuples (h, t, a, ζ, φ, τ). Here, h, t, and a denote the holder, target, and aspect, consistent with the definitions in subtask-I. ζ and φ represent the initial and flipped sentiments, respectively, highlighting the dynamic change in sentiment by the same speaker towards the same aspect of the same target. τ refers to a trigger that induces the sentiment transition, which is a pre-defined label among four categories: 1) introduction of new information, 2) logical argumentation, 3) participant feedback and interaction, and 4) personal experience and self-reflection. Since subtask-II shares multiple elements with subtask-I, it is natural to detect the flipping based on the results from subtask-I to minimize redundancy.
PanoSent: A Multimodal Conversational ABSA Dataset
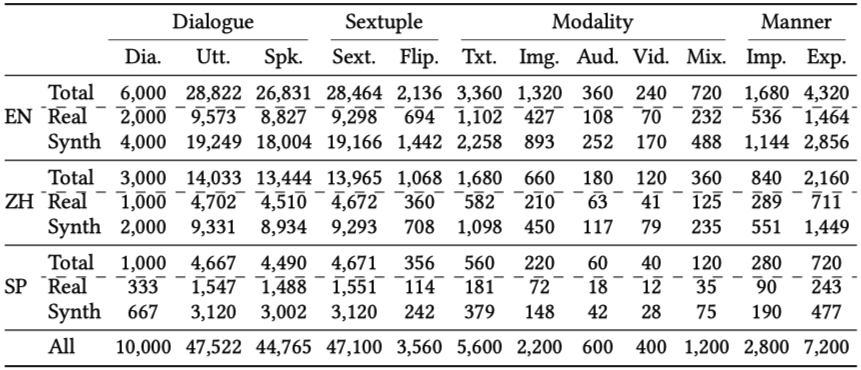
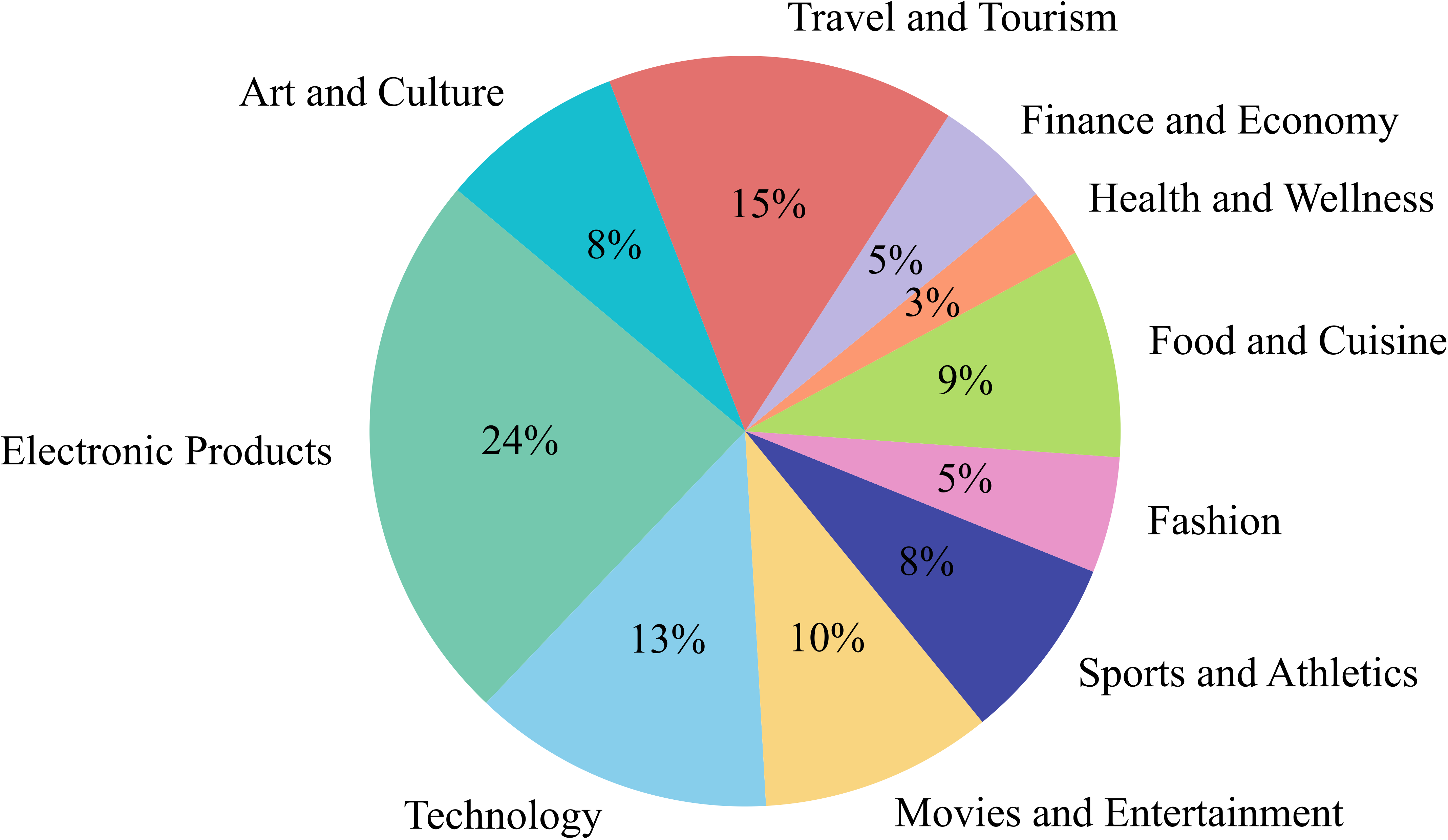
We contribute a large-scale, high-quality benchmark dataset, PanoSent, featuring multiple aspects: conversational contexts, multimodality, multilingualism, and multidomain.
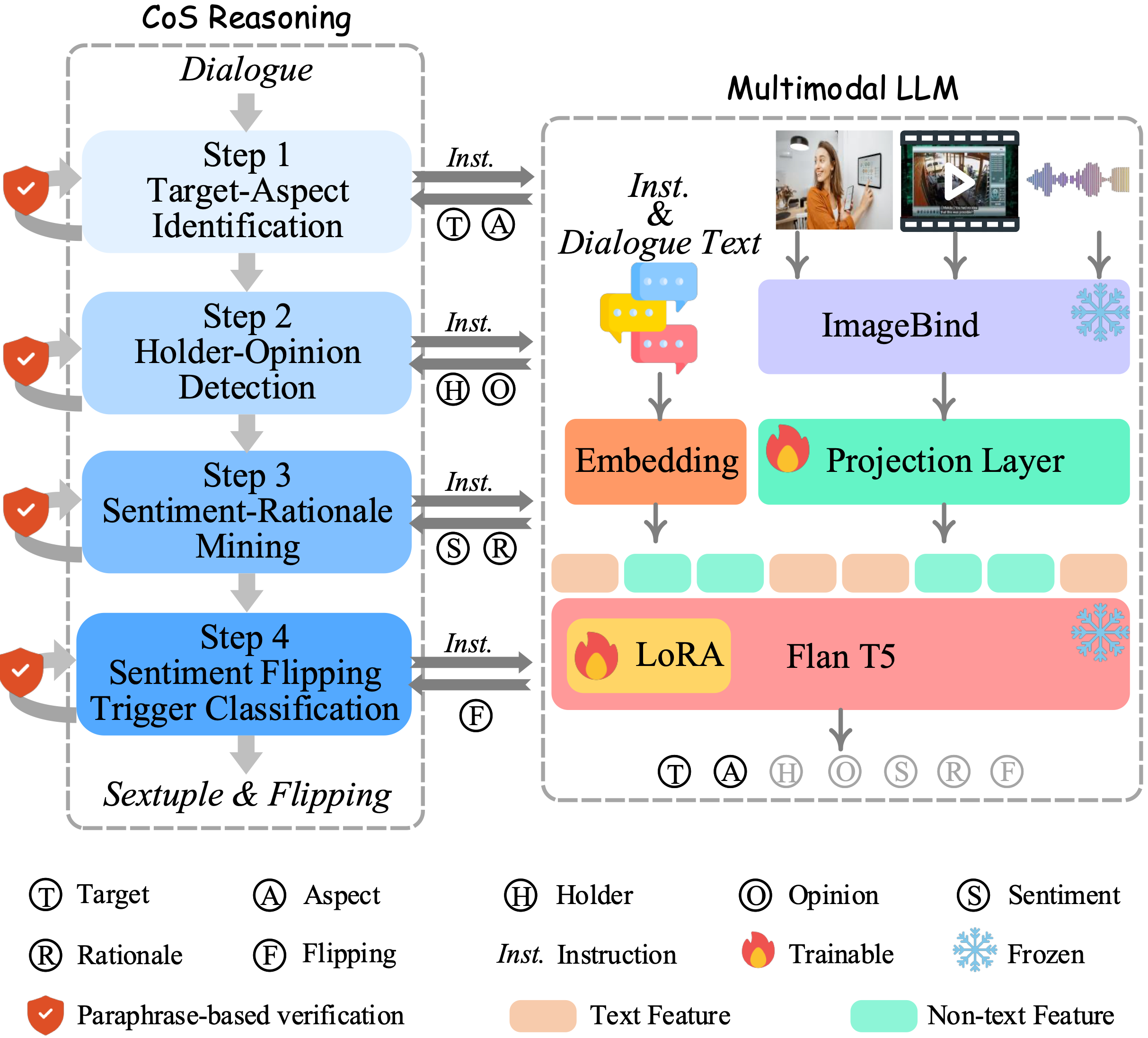
Sentica MLLM: Multimodal LLM Backbone
We develop a novel MLLM, namely Sentica. Specifically, we leverage ImageBind as the unified encoders for all three non-text modalities. Then, a linear layer connects ImageBind to LLM for representation projection.




{kind=link}